
Sunday, April 09, 2006
Continuous Integration and Configuration Management
As we said "yesterday", one of the most important tasks using agile methodologies is the "continuous integration".
This practice consists of extending the use of automatic and daily buils. If we've achieved the automatic building process, why don't we run it at every change we make to our product?
That is the key of continuous integration, but as you can imagine, it isn't so simple as it would seems at first glance.
First step in order to apply continuous integration is, as we said, take a turn for the better building process, making it automatic. In order to achieve it, we can use tools like Ant, Maven, the old known MAKE, Jam and so on, which allow us to launch all tasks in such a way our intervention isn't needed.
Once we achieved to run all steps, this process should be triggered automatically every time one change was done in the repository. We can do it easily thanks to all these tools, which will help us to schedule the building, although we would do it enabling a dedicated machine and managing commitment of all dev team to run a build process every time a change was registered. Ummm, I think it will be much better to install one tool, isn't it?
Companies handling huge code base give this aspect a great relevance. For instance: Microsoft, inside its Windows dev team, have a whole building lab: lots of servers and people in charge of getting builds and tests running properly every day.
Well, this model of continuous integration would be a big headache if you try to do it without mind.
Let's say we have a repostitory with our source code. We're using Subversion, but every other tools could be fine: CVS, Source Safe, Perforce, Pastic, etc. Each time we check one change in the repository, it's possible our product stops compiling properly (for example if you forgot to check-in one new file), or some bugs have been introduced, so we can say at that moment the repository is unstable. If we run a build process every time a change was made, many of these builds will fail. For instance: every afternoon we check-in all changes made during the day, even if these changes aren't completed, so if we build the product in that moment, probably it will fail. This is done by all programmers, so next morning the repository could be full of bugs and compilation errors, and if we need to deliver a new version quickly, we'll be in a difficult position.
Next, you can see a graphic showing this issue:
Each arrow means one change made in the repository, and as you can see, some changes have unstabilized our product, introducing bugs or compilation errors.
In order to follow continuous integration without headaches, we should arrange our development using several branches.
For this configuration management model, we have several alternatives, more usual are:
Each developed owns its own brach of code, where he/she work daily, making changes, etc. This is a private branch, so he/she will be able to do whatever he/she want with him/her code. Usually, that branch will be very unstable at the begining of the development, but it will become more and more stable as development makes progress.
At the moment of developer ends him/her work, a new version of that brach will be compiled, and test team (Quality Assurance) will check it. QA team will report all bugs found and dev team will fix most of them, until this new feature is completly stable and free of bugs. Then, a tag (or label) will be stamped on that branch, and it will be integrated (merged) into the main line of development. Due to integration task usually introduces new bugs, a new version will be built from just integrated main branch, so QA team will test again whether the new version is stable and free of bugs. When all possible bugs have been fixed, a new label will be stamped on the main branch and now we'll have a new feature integrated and minimized the time where the main repository stays unstable.
We can see this model next. Note main branch has much less "unstable zones" than previous model.
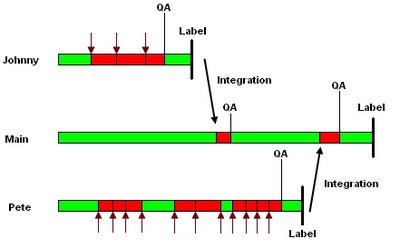
There is another model, very similar to previous, which consists of using a branch for each new feature to be developed, instead of use it for each developer in the team. If more than one developer work in the same feature, this is more advisable, because all developers will share code under development.
When the feature is completed, this branch makes dead and new branches should be created for next features.
Well, as you see, this topic isn't easy to manage and requires you some work and infrastructure. I'd recommend you try to make as automatic as you can all tasks for manage and created branches, making integrations, and so on.
But... where is our continuous integration in all this muddle? In the main branch them. All final and stable changes are registered in the main branch, after be developed and checked in other branch, so every integration was made, a new build process must be run in the main branch.
And finishing touch, you can place an "ambient orb" in you office, in order to every body can see the main branch state.
Automated Continuous Integration and the Ambient Orb
Using an Ambient Orb to show continuous integration build status
The Build Indicator Lamp
We don't go so far, and you?

This practice consists of extending the use of automatic and daily buils. If we've achieved the automatic building process, why don't we run it at every change we make to our product?
That is the key of continuous integration, but as you can imagine, it isn't so simple as it would seems at first glance.
First step in order to apply continuous integration is, as we said, take a turn for the better building process, making it automatic. In order to achieve it, we can use tools like Ant, Maven, the old known MAKE, Jam and so on, which allow us to launch all tasks in such a way our intervention isn't needed.
Once we achieved to run all steps, this process should be triggered automatically every time one change was done in the repository. We can do it easily thanks to all these tools, which will help us to schedule the building, although we would do it enabling a dedicated machine and managing commitment of all dev team to run a build process every time a change was registered. Ummm, I think it will be much better to install one tool, isn't it?
Companies handling huge code base give this aspect a great relevance. For instance: Microsoft, inside its Windows dev team, have a whole building lab: lots of servers and people in charge of getting builds and tests running properly every day.
Well, this model of continuous integration would be a big headache if you try to do it without mind.
Let's say we have a repostitory with our source code. We're using Subversion, but every other tools could be fine: CVS, Source Safe, Perforce, Pastic, etc. Each time we check one change in the repository, it's possible our product stops compiling properly (for example if you forgot to check-in one new file), or some bugs have been introduced, so we can say at that moment the repository is unstable. If we run a build process every time a change was made, many of these builds will fail. For instance: every afternoon we check-in all changes made during the day, even if these changes aren't completed, so if we build the product in that moment, probably it will fail. This is done by all programmers, so next morning the repository could be full of bugs and compilation errors, and if we need to deliver a new version quickly, we'll be in a difficult position.
Next, you can see a graphic showing this issue:
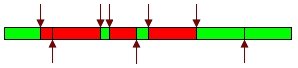
Each arrow means one change made in the repository, and as you can see, some changes have unstabilized our product, introducing bugs or compilation errors.
In order to follow continuous integration without headaches, we should arrange our development using several branches.
For this configuration management model, we have several alternatives, more usual are:
Each developed owns its own brach of code, where he/she work daily, making changes, etc. This is a private branch, so he/she will be able to do whatever he/she want with him/her code. Usually, that branch will be very unstable at the begining of the development, but it will become more and more stable as development makes progress.
At the moment of developer ends him/her work, a new version of that brach will be compiled, and test team (Quality Assurance) will check it. QA team will report all bugs found and dev team will fix most of them, until this new feature is completly stable and free of bugs. Then, a tag (or label) will be stamped on that branch, and it will be integrated (merged) into the main line of development. Due to integration task usually introduces new bugs, a new version will be built from just integrated main branch, so QA team will test again whether the new version is stable and free of bugs. When all possible bugs have been fixed, a new label will be stamped on the main branch and now we'll have a new feature integrated and minimized the time where the main repository stays unstable.
We can see this model next. Note main branch has much less "unstable zones" than previous model.

There is another model, very similar to previous, which consists of using a branch for each new feature to be developed, instead of use it for each developer in the team. If more than one developer work in the same feature, this is more advisable, because all developers will share code under development.
When the feature is completed, this branch makes dead and new branches should be created for next features.
Well, as you see, this topic isn't easy to manage and requires you some work and infrastructure. I'd recommend you try to make as automatic as you can all tasks for manage and created branches, making integrations, and so on.
But... where is our continuous integration in all this muddle? In the main branch them. All final and stable changes are registered in the main branch, after be developed and checked in other branch, so every integration was made, a new build process must be run in the main branch.
And finishing touch, you can place an "ambient orb" in you office, in order to every body can see the main branch state.
Automated Continuous Integration and the Ambient Orb
Using an Ambient Orb to show continuous integration build status
The Build Indicator Lamp
We don't go so far, and you?
posted by JM : 1:04 pm


![]()
