
Thursday, April 27, 2006
Battlewizard: our mobile games development platform

One of most important troubles developing mobile games is the really broad range of target devices to support during each development.Although we develop for handsets with Java support (specifinally J2ME, CLDC 1.1 and CDC 1.1), we should take into account that it's quite different develop to one Nokia 3100 than another Sony Ericsson S700. Their screens are different, their computation power are different and their supported API are quite different (S700 supports 3D through JSR-184)
This "fragmentation problem" affects us in many ways: we must manage all graphic content to show in the screen, since screen sizes, number of colours and resolution may vary; we must manage game package size, due each handset allows one maximum size; we must manage our heap occupation; we must manage all amount of persistent data (Record Store)... and no end of aspects more.
The traditional solution to this problem is to develop the same game several times, trying to reuse as much code as you can. That is: a big team develops a game, but repeat their code for all devices to support, trying to extract and reuse every common code, and changing some sections to fit each handset peculiarity. This generates tons of repeated code, prone to errors, and very stiff to be changed.
Lets think during last stages in game development, most great ideas come up, and those ones are which becomes the game something funny and playable. At that point, all code is written, so we must try to make this code as flexible and agile as we can.
This approach needs a large team of developers, at least one programmer for each device to support, and it is followed by some of most large mobile game companies, like GameLoft.
 Another possible solution is to develop the whole game for one single platform, and contract other company (usually low-cost one from one developing country like China). This company will be in charge of porting the game to others devices and platforms. Regardless ethic opinions (who realized about working conditions in Third World countries?), this solution needs more money and extra coordination between us and the other company. Needless to say, once porting has been completed, game code becomes unchangeable, and we don't be able to add or remove features for specific devices.
Another possible solution is to develop the whole game for one single platform, and contract other company (usually low-cost one from one developing country like China). This company will be in charge of porting the game to others devices and platforms. Regardless ethic opinions (who realized about working conditions in Third World countries?), this solution needs more money and extra coordination between us and the other company. Needless to say, once porting has been completed, game code becomes unchangeable, and we don't be able to add or remove features for specific devices.Third solution is called Battlewizard: with our tool it's possible to develop one game, with one code base, and working for all handsets you want to support. Even one single programmer would build up to 150 or 200 different versions without effort. Is it magic? No it isn't, simply "fragmentation problem" is tackled from the begining of the development and using right tools.
Do you want to release your game for small screens (128x128) and big ones (240x320)? Just define both profiles, add all graphic content taking into account each screen sizes and build all versions for all devices which fit in those screen sizes.
Do you need to deliver you game for MIDP 2.0 and Nokia handsets? Just define both profiles, and when game was built, specific engine will be used for each kind of device.
Battlewizard consists of several modules and layers:
- An Integrated Development Environment (IDE), with you can add all game contents: graphics, fonts, sprites, levels, AI behaviours, device profiles, etc.
- A programming API to handle all contents built with the Battlewizard IDE and certain task and tool usually needed in games: collision detection, several isometric renderers, etc.
- One specific implementation for each kind of programming API supported by Battewizard, in such a way we'll have MIDP 2.0m MIDP 3.0 (under definition), nokiaui and much more APIs. Depending on version to generate, one specified implementation will be used.
- A middleware for on-line games, which allows you download some game contents once it's installed in your phone.
- A internal scripting engine, to send executable code through GPRS/GSM and be able to modify agents behaviour, or add new dynamic content to your games (for instance: new game logic, new kind of enemies, etc.)
 Battlewizard supports any J2ME games (both CLDC and CDC), although we're working in Symbian and Brew versions.
Battlewizard supports any J2ME games (both CLDC and CDC), although we're working in Symbian and Brew versions.But as usual, magic doesn't exists: main inconvenient with this solution is all game version must fit at minimun of all supported devices. For instance: if we supports a range of devices with heap sizes from 500 KB up to 4 MB, our game should be programmed taking into account memory peaks for 500 KB device, although most powerful device memory will be wasted.
Well, I think it was a good introduction . Next we'll talk more deeply about Battlewizard and all task we can achieve with it.
Saturday, April 22, 2006
Think about profiles and capabilities instead of devices
Some time ago we started changing the architecture of our tools and our way of thinking about the platforms we are developing for. We move from thinking about devices to start thinking about profiles and capabilities.
Our headache begins when our developments oriented to some devices need to be updated for new devices arriving to the market, and so many updates makes our tools less intuitive and more complex of using. Gradually with our old experience in systems like UAProf, we started to change our way of thinking to be more agile and making our tools more natural.
The market is creating new devices very fast and the properties of these new devices, although stable, change it values constantly. For example, Nokia decides frequently to change the 40 Series screen size, HEAP memory and the RMS. If we observe this kind of changes from all devices manufacturers, we need to update our devices data base too frequently and we haven’t time and infinite resources.
This problem move us to think in the development community and what decisions are they taking. We found that some communities oriented to J2ME like J2ME Polish , created a J2ME devices data base designed to know differences between different devices; we also found other communities like WAP developers, that have been fighting against this problem more time and basing their solutions in systems like UAProf , have developed data bases like WURFL.
This way move us to think as we did in older times with WAP problems, because at the end our objective is the same, show content in mobile devices: THINK ABOUT CAPABILITIES.
Using capabilities consists in not knowing about brands or models and things like that, better thinking about screen sizes, audio and video formats, J2ME properties, available memory, etc. Using this way, we create the profile concept, which is no more than grouping some capabilities.
Now, our content can be managed in an independent way from devices data base. Our devices data base will grow and our content will be adjusted to the new devices depending on their capabilities.
For example, if I create a “Medium-Low” profile where screen size moves from 128x128 to 128x160, supporting PNG as image format, where my HEAP limit size is 512 KB, where my JAR limit size is 125 KB and supporting MIDI as audio format, for sure that a group of devices from different manufacturers will match with this characteristics now and next year.
Our way of facing the fragmentation problem with mobile phones is thinking about profiles and capabilities. The objective of developing thinking about devices can’t be afford by small and medium companies and will be avoid in big companies in the moment they decide reducing costs.
Sunday, April 09, 2006
Continuous Integration and Configuration Management
This practice consists of extending the use of automatic and daily buils. If we've achieved the automatic building process, why don't we run it at every change we make to our product?
That is the key of continuous integration, but as you can imagine, it isn't so simple as it would seems at first glance.
First step in order to apply continuous integration is, as we said, take a turn for the better building process, making it automatic. In order to achieve it, we can use tools like Ant, Maven, the old known MAKE, Jam and so on, which allow us to launch all tasks in such a way our intervention isn't needed.
Once we achieved to run all steps, this process should be triggered automatically every time one change was done in the repository. We can do it easily thanks to all these tools, which will help us to schedule the building, although we would do it enabling a dedicated machine and managing commitment of all dev team to run a build process every time a change was registered. Ummm, I think it will be much better to install one tool, isn't it?
Companies handling huge code base give this aspect a great relevance. For instance: Microsoft, inside its Windows dev team, have a whole building lab: lots of servers and people in charge of getting builds and tests running properly every day.
Well, this model of continuous integration would be a big headache if you try to do it without mind.
Let's say we have a repostitory with our source code. We're using Subversion, but every other tools could be fine: CVS, Source Safe, Perforce, Pastic, etc. Each time we check one change in the repository, it's possible our product stops compiling properly (for example if you forgot to check-in one new file), or some bugs have been introduced, so we can say at that moment the repository is unstable. If we run a build process every time a change was made, many of these builds will fail. For instance: every afternoon we check-in all changes made during the day, even if these changes aren't completed, so if we build the product in that moment, probably it will fail. This is done by all programmers, so next morning the repository could be full of bugs and compilation errors, and if we need to deliver a new version quickly, we'll be in a difficult position.
Next, you can see a graphic showing this issue:
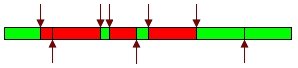
Each arrow means one change made in the repository, and as you can see, some changes have unstabilized our product, introducing bugs or compilation errors.
In order to follow continuous integration without headaches, we should arrange our development using several branches.
For this configuration management model, we have several alternatives, more usual are:
Each developed owns its own brach of code, where he/she work daily, making changes, etc. This is a private branch, so he/she will be able to do whatever he/she want with him/her code. Usually, that branch will be very unstable at the begining of the development, but it will become more and more stable as development makes progress.
At the moment of developer ends him/her work, a new version of that brach will be compiled, and test team (Quality Assurance) will check it. QA team will report all bugs found and dev team will fix most of them, until this new feature is completly stable and free of bugs. Then, a tag (or label) will be stamped on that branch, and it will be integrated (merged) into the main line of development. Due to integration task usually introduces new bugs, a new version will be built from just integrated main branch, so QA team will test again whether the new version is stable and free of bugs. When all possible bugs have been fixed, a new label will be stamped on the main branch and now we'll have a new feature integrated and minimized the time where the main repository stays unstable.
We can see this model next. Note main branch has much less "unstable zones" than previous model.

There is another model, very similar to previous, which consists of using a branch for each new feature to be developed, instead of use it for each developer in the team. If more than one developer work in the same feature, this is more advisable, because all developers will share code under development.
When the feature is completed, this branch makes dead and new branches should be created for next features.
Well, as you see, this topic isn't easy to manage and requires you some work and infrastructure. I'd recommend you try to make as automatic as you can all tasks for manage and created branches, making integrations, and so on.
But... where is our continuous integration in all this muddle? In the main branch them. All final and stable changes are registered in the main branch, after be developed and checked in other branch, so every integration was made, a new build process must be run in the main branch.
And finishing touch, you can place an "ambient orb" in you office, in order to every body can see the main branch state.
Automated Continuous Integration and the Ambient Orb
Using an Ambient Orb to show continuous integration build status
The Build Indicator Lamp
We don't go so far, and you?

![]()
